
Abordons dans cet article un moyen d’automatiser le déploiement de son code Terraform : les outils de CI/CD intégrés à Gitlab (et les runners associés).
Nous détaillerons une pipeline constituée de 3 jobs pour l’initialisation, la planification et l’application d’un manifeste Terraform. Avec une validation manuelle avant la création effective des ressources. En bonus nous verrons comment planifier la destruction de l’infrastructure pour limiter les coûts dans le cadre d’un POC.
Je supposerais ici que vous êtes déjà familier, au moins dans les grandes lignes, avec l’outil de CI proposé pas Gitlab. Si ce n’est pas le cas je vous conseille de lire le quick start qui vous donnera une bonne idée.
Grossièrement il s’agit d’éditer un fichier .gitlab-ci.yml à la racine de votre projet qui contiendra la logique d’un ensemble de tâches qui seront éxécutées sur des serveurs mis à disposition par Gitlab.com à chaque push sur votre dépot.
Attention tout de même, le service n’est pas complétement gratuit : vous disposez de 2000 minutes gratuites de temps d’éxécution par mois. Vous pouvez suivre votre quota à cette url : https://gitlab.com/profile/pipeline_quota
Avant-propos
Disclaimer
Ce code a été écrit dans le cadre d’un POC. Certains choix ont été faits pour des raisons de praticité spéficiques au projet, ou par manque d’alternative du fait d’une instance Gitlab ne possédant pas les dernières mises à jours.
Cet exemple n’est pas le reflet des bonnes pratiques pour gérer un déploiement Terraform en production mais je suppose qu’il peut tout de même intéresser certains.
Options communes
La définition des jobs dans gitlab CI/CD se présente sous la forme d’un fichier yaml (.gitlab-ci.yml) dont voici un extrait :
1 | job_name: |
Détaillons brièvement cet extrait qui contient plusieurs paramètres qui seront présent dans les jobs que nous aborderons par la suite :
- job_name est le nom du job, surprenamment…
- stage permet d’ordonnancer les jobs, nous en aurons trois défini en amont : init, plan et deploy qui s’éxécuteront l’un après l’autre.
- image permet de spécifier une image docker dans laquelle les commandes du job seront éxécutées. Nous utiliserons une image Hashicorp contenant déjà le binaire Terraform.
- only permet d’appliquer un filtre spécifiant que ce job ne s’éxécutera que pour la branche master.
- script contient les commandes à exécuter par le job.
Pour nos 3 jobs de déploiement (initialisation, planification et application) nous retrouverons toutes ces options.
Les stages seront en pratique déclarés en amont via les directive suivantes :
1 | stages: |
Terraform et l’automatisation
Dans un contexte d’automatisation on utilise les commandes Terraform de manière légèrement différentes. Plutôt que de faire un apply “dynamique”, on génère un fichier de planification via la commande plan, puis on utilise ce fichier comme input pour la commande apply. On évite également la possibilité d’input dynamique des variables avec le paramètre -input=false.
Et optionnellement on peut définir la variable d’environnement TF_IN_AUTOMATION pour que terraform modifie ses outputs en conséquence.
La simple existence de la variable TF_IN_AUTOMATION suffit : peu importe sa valeur
Les étapes sont les suivantes :
- Initialisation du répertoire de travail terraform (
terraform init -input=false) - Création d’un fichier listant tous les changements à appliquer (
terraform plan -out=tfplan -input=false) - Validation humaine et / ou vérifications automatisées sur le fichier de plan
- Application des changements listés dans le plan (
terraform apply -input=false tfplan)
Les jobs de déploiement continu que nous abordons ci après permettent de gérer ces 4 étapes.
Initialisation
En plus des options de configuration communes évoquées en début d’article, le job d’initialisation ajoute une directive artifacts et les commandes de script suivantes :
1 | init_stack: |
Mise à part la dernière commande de la section script : terraform init -input=false qui nous est désormais familière (et la première qui permet simplement de se déplacer dans le répertoire contenant le code terraform), il y a quelques nouveautées.
Explicitons …
Override du backend
La deuxième commande du script fait en réalité appel à un fichier de template stocké sous <racine>/ci/templates/tfstates.tf.tpl qui contient :
1 | terraform { |
L’idée de cette commande est de remplacer les placeholder_quelquechose par des variables définies en amont afin de créer un fichier tfstates_override.tf.
Les fichiers dont le nom se terminent par _override ont une fonction particulière dans terraform : il permettent de remplacer la définition de ressources portant le même nom que celles définies dans ce type de fichier, si elles existent, sans lever d’erreurs (comme le ferait une ressource dupliquée).
Plus simplement : ce fichier vient écraser la configuration du backend s3 contenue dans le dépot (si elle existe) pour la remplacer par une configuration créée à la volée à partir de variables pré-définies.
La définition de ces variables se fait soit directement dans l’interface graphique de Gitlab (nous y reviendrons) soit en amont dans le fichier .gitlab-ci.yml avec le bloc suivant :
1 | variables: |
Si on décortique la deuxième commande script on obtient donc :
- le sed qui permet de remplacer les placeholders par les variables instanciées précédemment
- le < qui permet de spéficier à sed le fichier source pour effectuer les remplacements (notre template stocké dans le dépot)
- le > qui spéficie le fichier de sortie : notre tfstates_override.tf qui viendra surcharger la configuration de notre backend.
Par ce biais on garde la main sur l’endroit ou sont stockés les states de notre manifeste, et ce même si ce manifest contient déjà une configuration de backend. Utile pour décorréler la gestion de plusieurs environnements.
Pour éviter d’introduire des changements au statut git, j’ajoute le fichier tfstates_override.tf au .gitignore de mon dépot.
Nous aurions également pu définir plusieurs fichiers de configuration de backend et utiliser l’option
-backend-config=PATHde la commande terraform init mais cela nous force à exposer toutes les configurations au sein du dépot. Il peut dans certains cas être préférable d’isoler ces informations, les variable d’environnement définies via l’UI Gitlab étant une alors option.
Initialisation des secrets
Dans la même optique d’isolation, certaines variables ne doivent pas apparaitre dans le dépot git. Mots de passe ou secrets en tout genres doivent être gérés autrement.
Il existe des solutions dédiées et sécurisées pour ce besoin, mais dans notre cas nous considérerons que stocker ces secrets en tant que variables d’environnement dans Gitlab et créer un fichier de secrets seulement dans le contexte du déploiement est une solution suffisante.
C’est exactement ce que fait la troisième commande :
1 | echo -e "db_user_password = \"${DB_USER_PASSWORD}\"\nadmin_password = \"${ADMIN_PASSWORD}\"\n" > secrets.tfvars |
dont l’output est :
1 | db_user_password = "valeur_stockée_dans_gitlab" |
Pour définir des variables d’environnement dans Gitlab il faut aller, depuis la sidebar d’administration, dans l’onglet Settings > CI / CD puis étendre la section Variables. Vous pourrez définir ici un ensemble de clef (et valeurs associées) telle que DB_USER_PASSWORD utilisée dans l’example.
Il ne reste plus qu’à mettre ce fichier en input d’un terraform plan et le tour est joué.
Artifacts
Les artifacts permettent de répondre à la problématique posée par l’isolation des jobs. En effet chacun s’exécute dans un “contexte” isolé (un nouveau container docker), et toutes les modifications apportées au dépot pendant un job disparaissent une fois ce job terminé.
Or l’initialisition de terraform créé notamment un répertoire .terraform local qui est nécessaire pour les commandes plan et apply suivantes. Il convient donc de s’assurer que celui ci est persisté entre les jobs, et c’est le rôle des artifacts. Un artifact est un zip, créé après l’exécution du job, contenant une liste de fichiers et répertoires qui seront dé-zippés dans le contexte des jobs suivants avant l’exécution des tâches de ces derniers.
Dans notre cas nous avons la configuration suivante :
1 | artifacts: |
La directive la plus importante est la directive paths qui permet de spécifier les répertoires et fichiers à persister. Nous persistons donc le répertoire .terraform ainsi que les deux fichiers créés pendant notre job d’initialisation. Les commandes plan et apply des jobs suivants n’auront donc aucun problème pour s’exécuter.
Les autres directives permettent de nommer l’artifact, de spécifier qu’il n’est créé que si aucune erreurs n’est rencontré au cour du job, et de spécifier sa destruction 6h après sa création.
La variable CI_JOB_ID est une variable d’environnement par défaut de gitlab CI, elle permet de rendre le nom d’artifact un peu plus unique.
Planification
Dans ce job nous créons le fichier de “plan” qui sera fourni au dernier job pour application. L’avantage est que cela permet de mettre une pause avant l’application et de procéder à des vérifications avant de confirmer ou infirmer la mise à jour de l’infrastructure.
Vous vous doutez bien que ce fichier devra exister dans le dernier job et sera donc lui aussi persisté par le biais d’un artifact :
1 | build_stack: |
Rien de bien nouveau ici.
On remarque notamment l’utilisation du fichier secrets.tfvars persité précédemment, et la création d’un nouvel artifact pour le fichier tfplan.
La nouvelle directive dependencies permet d’expliciter la dépendance au job précédent (init_stack) mais n’est en réalité pas indispensable. En effet les stages sont exécutés séquentiellement et dans l’ordre défini en amont (init > plan > deploy). L’init est donc toujours réalisé avant le plan. Et par défaut tous les artifacts sont récupérés automatiquement avant l’éxécution d’un job.
Cette directive permet en l’occurence de ne récupérer que les artifacts provenant des jobs explicitement listés. Dans notre cas cela ne change rien mais à tire personnel j’aime que cette dépendance soit clairement visible.
Application
Les deux dernières étapes (validation et application) sont réalisées au cours de ce dernier job. Nous ne découvrirons que la directive when à ce stade :
1 | deploy_stack: |
Ce dernier job se nomme donc deploy_stack, il fait parti du stage deploy, s’appuie sur les artifacts des deux jobs précédents pour lancer la commande apply finale.
La directive when: manual est celle qui permet d’introduire une pause pour validation. Cela informe gitlab CI que le job ne doit en réalité pas être lancé automatiquement : l’interface gitlab se contentera de présenter un bouton play qu’il faudra cliquer pour lancer la mise à jour de l’infrastructure.
Voici à quoi cela ressemble :

Libre a vous d’aller consulter l’output du job de planification précédent pour confirmer les changements avant de lancer l’apply.
Destruction
Gitlab-CI ne permet pas de définir simplement plusieurs pipelines au sein d’un même projet. Pour pouvoir décorréler les jobs permettant de déployer l’infrastructure de celui permettant de la détruire je me suis reposé sur la fonctionnalitée de schedule. Celle ci permet de planifier l’exécution de la pipeline à heure fixe via une syntaxe cron, et de filtrer les jobs à jouer selon si la pipeline en cours est planifiée ou non.
La configuration de la planification d’une exécution se fait via l’UI Gitlab. Depuis l’onglet de configuration à gauche, accédez à la section CI/CD puis à Schedules. Il vous suffit alors de cliquer sur New Schedule pour planifier une exécution récurrente. Par exemple tous les soirs à 17h :
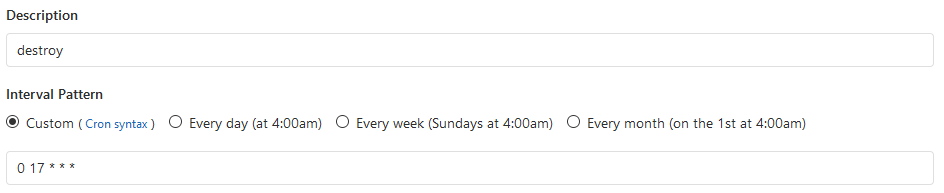
L’utilisation de cette fonctionnalité passe par l’ajout d’une option except schedules sur les jobs existant et la définition d’un ultime job :
1 | destroy_stack: |
Nous reprenons ici les concepts du job d’initialisation pour surcharger le backend et créer un fichier de secret. La différence réside bien sûr dans la commande terraform qui se charge de détruire la stack.
La directive only permet de s’assurer que ce job ne sera lancé que dans le cas où la pipeline est trigger par notre planification, et pas sur les push ou lancement manuel de celle ci. En parallèle il faut modifier les jobs précédents pour s’assurer qu’ils ne tournent pas sur une planification en leur ajoutant :
1 | except: |
Nous avons désormais une CI qui permet de déployer ou mettre à jour une infrastructure à chaque push / merge sur master (ou manuellement) et de détruire cette dernière tous les jours à 17h. Yay! 😄
Pour conclure
Les méthodes utilisées dans cet article ne sont certainement pas parfaites. Mais je me dit que cela peut faire une bonne introduction et j’espère que vous en aurez tiré quelque chose.
N’hésitez pas à me faire part de vos retours, remarques ou mêmes questions =).
Je copie colle ici quelques liens que j’ai parcouru et qui peuvent être utiles pour approfondir ou approcher le sujet différement :
learn.hashicorp.com - Running Terraform in Automation : Les instructions hashicorp pour déployer terraform automatiquement.
docs.gitlab.com - GitLab CI/CD Pipeline Configuration Reference : Tous les détails des options de configuration de gitlab CI.
docs.gitlab.com - GitLab Runner Docs : pour s’affranchir de la limite des 2000 minutes de compute gratuites.
terraform.io - Partial Backend Configuration : Pour des alternative à l’override du backend.
Et pour terminer le code complet disponible juste après.
Le code complet
1 | variables: |